This release brings significant performance and scalability upgrades in key product areas: Merge, Teamwork Cloud project load, Teamwork Cloud project saving, table loading, Excel and CSV files import, and such common modeling tool operations as Copy/Paste, Find, Numbering, Element Selection, and Validation.
Version 2021x adds the ability to use layers in diagrams, automatically create legends, present diagrams or predefined sequences of diagrams in full screen to stakeholders, create compositions and aggregations in matrices, and use predefined element type filters when searching for the necessary model elements. Additionally, the Excel/CSV file import functionality has been reviewed and refreshed, and numerous improvements to Excel/CSV synchronization functionality in tables have been added.
Last but not least, project merge has been extended to give users the option to show only the changes in directly modified diagrams, hide Target and Equivalent Changes by default, and choose a specific ancestor calculation algorithm depending on merge scenario and expected outcome.
Download the newest MagicDraw version at nomagic.com or contact your sales representative. Don't forget to give us your feedback on LinkedIn, Twitter, or Facebook. For further information, please check the latest documentation.
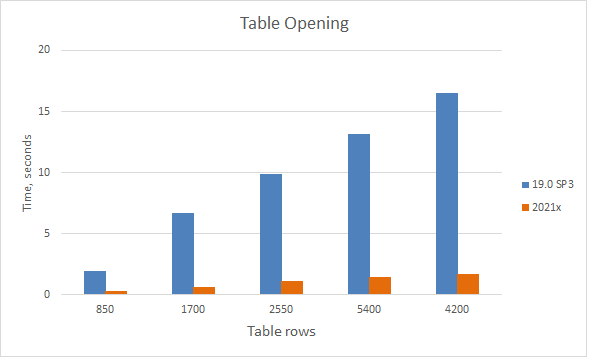
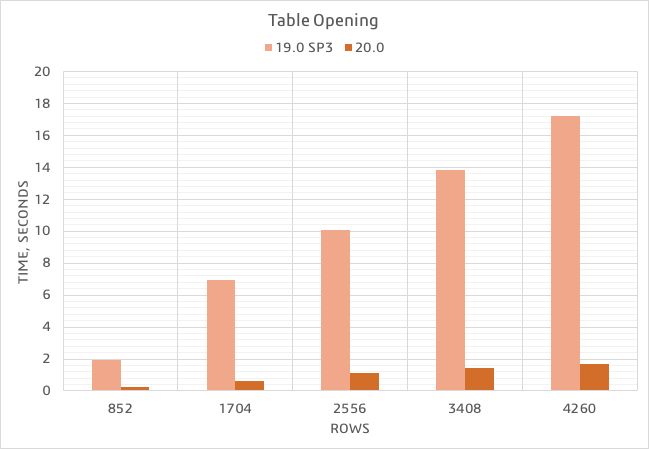
Experience enhanced table loading and scrolling performance! Thanks to the newly-introduced Load Partially mode, data is now loaded in only visible rows. There is no longer a need to wait until data is calculated in the entire table. Additionally, fast scrolling has improved; it is now considerably smoother.
A chart comparing the opening time of Requirement Table having 7 standard columns with a different number of requirements.
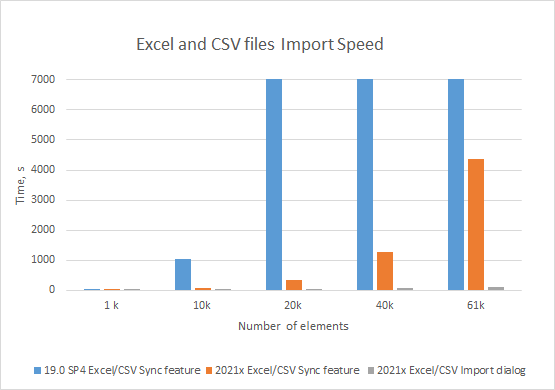
The import performance of data from an Excel or CSV file into the modeling tool adds a great experience while managing a large scope of data. The data import time using the table sync feature is significantly faster compared with the previous version (19.0 SP4). Also, the data import using the new Excel/CSV Import dialog is even better in comparison to Excel/CSV Sync feature. The import of 61k elements takes only 2 minutes (see the chart below).
A chart comparing data import from Excel and CSV files using the Excel/CSV Sync and Excel/CSV Import dialogs.
Common Operations
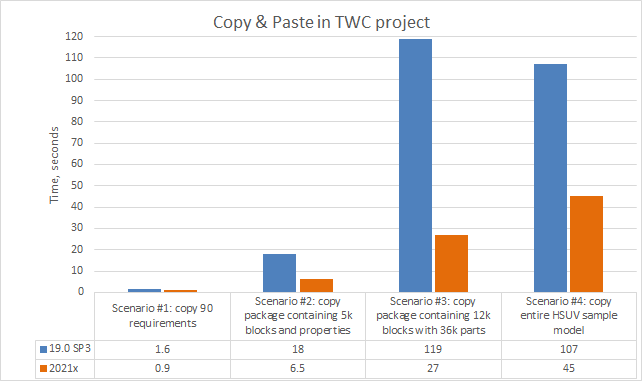
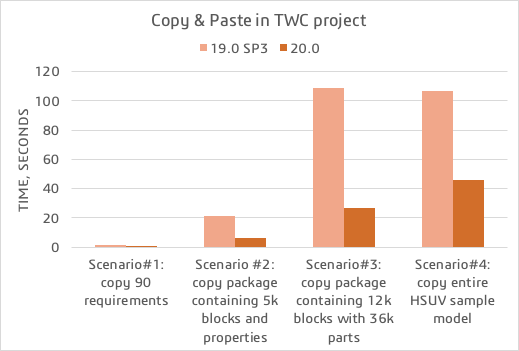
Copy/Paste. Now you can copy and paste data 2-4 times faster depending on the specific scenario.
A chart comparing the copy&paste operation time in various scenarios.
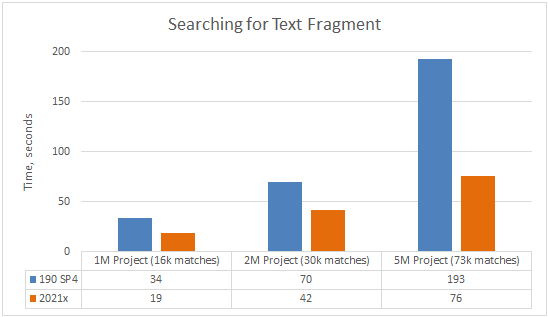
Find. The search speed in all texts has increased by 70-150% compared to 19.0 SP4.
A chart comparing the Find operation speed in 19.0 SP4 and 2021x projects containing 1M, 2M, and 5M elements (including used projects).
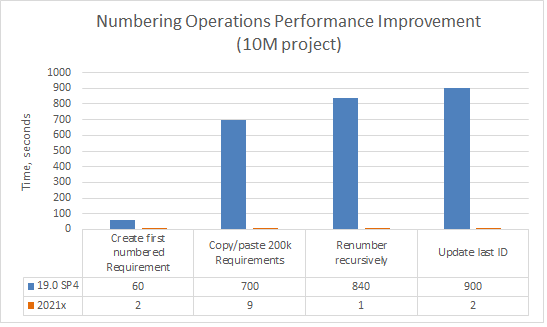
Numbering. Creating the first numbered element, copying/pasting numbered elements, renumbering elements recursively, and updating the last element ID is now 30-840 times faster.
A chart comparing the Numbering operations speed in 19.0 SP4 and 2021x projects containing 10M elements (including used projects).
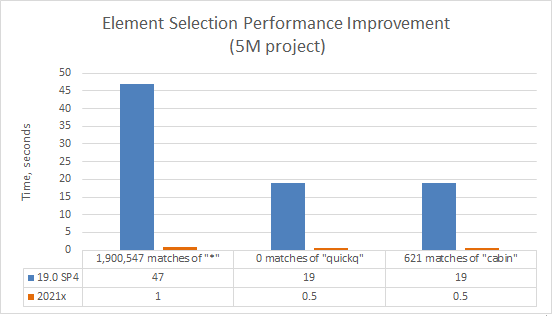
Element Selection. Now you can search and select the needed elements (e.g., in the Select Element and Quick Find dialogs as well as drop-down lists) approximately 40-50 times faster.
A chart comparing the element selection speed in 19.0 SP4 and 2021x projects containing 5M elements (including used projects).
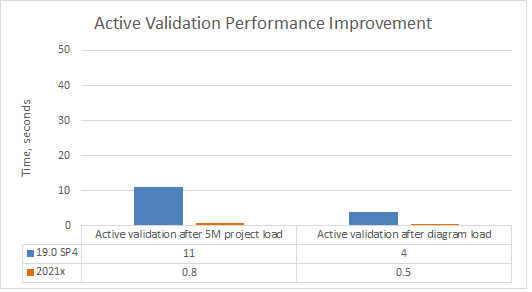
Validation. The active validation of the model now takes less than a second (0.8s after 5M project load and 0.5s after diagram load).
A chart comparing the active validation speed after the project and diagram load in 19.0 SP4 and 2021x projects containing 5M elements (including used projects).
Profiling Changes in the UML 2.5.1 Metamodel
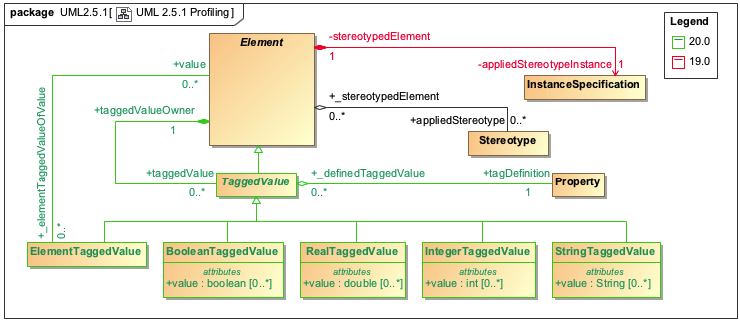
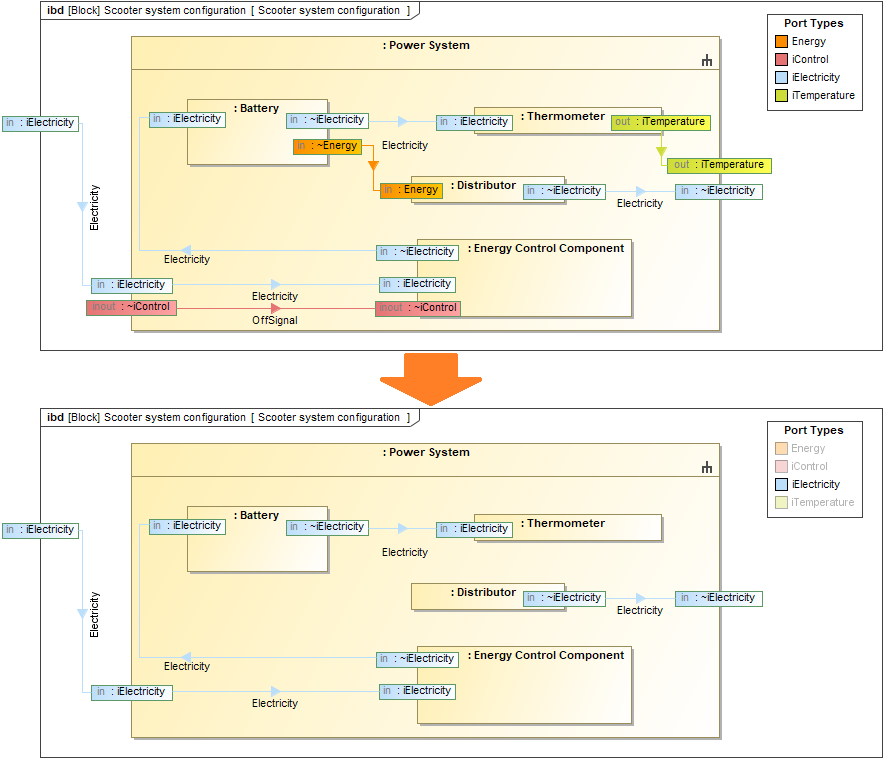
Significant changes have been implemented in the UML metamodel for improved performance. The InstanceSpecifications, Slots, and ValueSpecifications are no longer used to store profiling data. Instead, new model element types and properties are introduced, while some have been removed (see the diagram below).
Profiling changes in the UML metamodel.
As shown in the figure above, Element references the TaggedValue that is used to specify the Boolean, Integer, Real, String, or Element values of the applied stereotype properties. This approach uses fewer model elements to store profiling data, which leads to a decrease in the total number of elements in SysML and UAF projects by 40-80%.
Note. Expressions based on the previously implemented profiling data storing metamodel no longer work, meaning that they have to be updated manually.
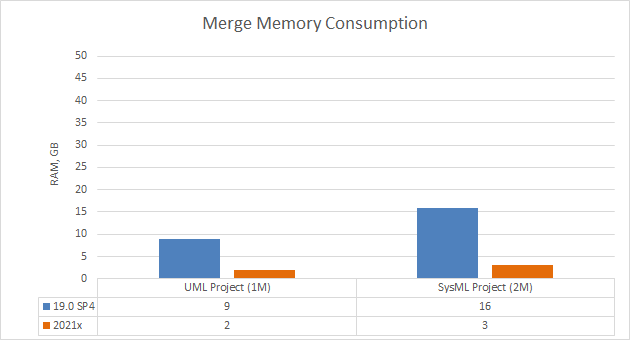
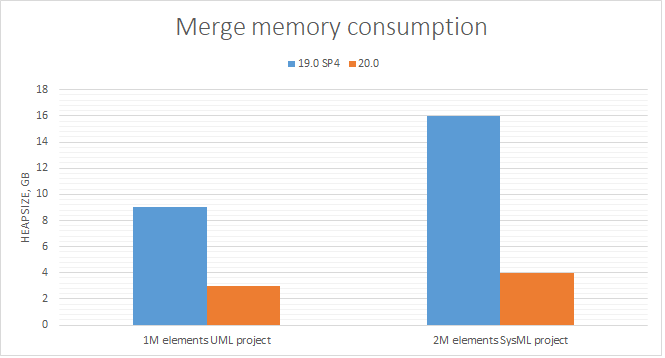
Project Merge has undergone considerable performance improvements. The modeling tool version 2021x requires approximately 4-5 times less memory to successfully merge two server project branches, compared to 19.0 SP4.
A chart comparing merge memory consumption in different modeling tool versions.
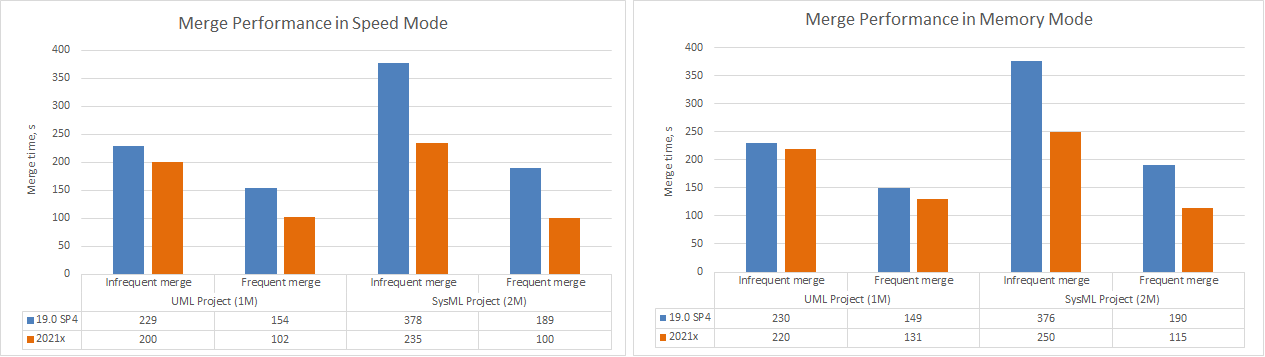
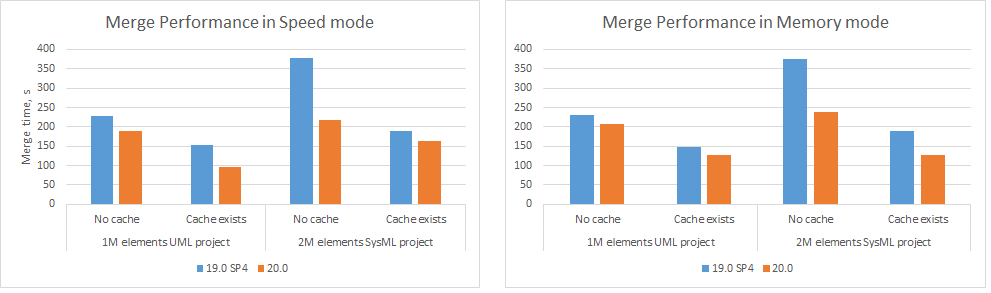
Furthermore, the merge operation speed has increased by 20-70% in 2021x compared to 19.0 SP4. Both frequent (between close project versions) and infrequent (between distant project versions) merges can now be performed much faster!
Charts comparing merge performance in Speed and Memory modes.
TWC Project Load
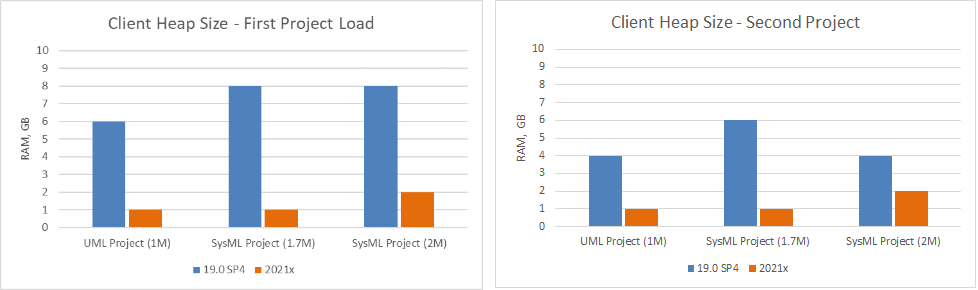
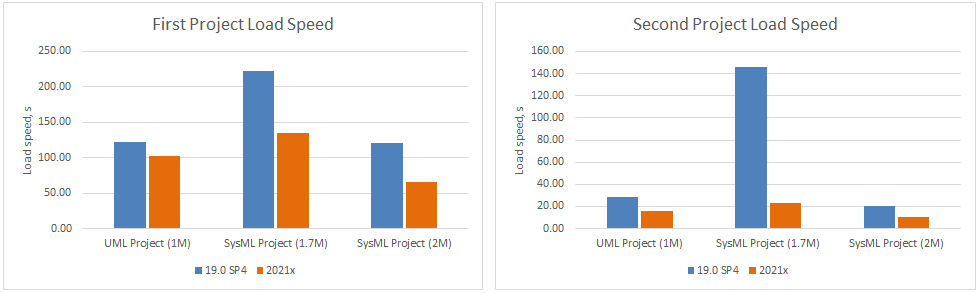
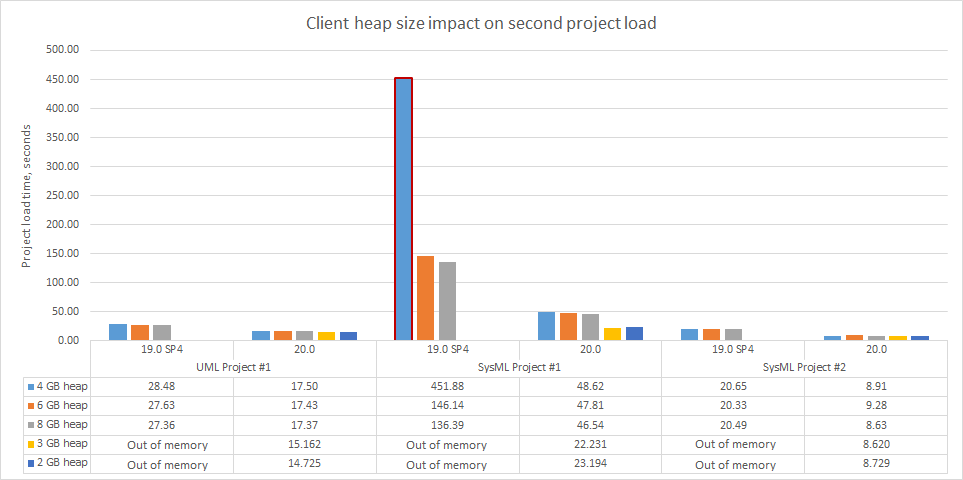
Project load memory and speed improvements have been implemented for Teamwork Cloud. The modeling tool now requires only 2GB of heap to load a 2M SysML project (first and second time) when working with TWC projects compared to 8GB in 19.0 SP4. Additionally, as a result of the UML metamodel changes, SysML projects are now opened 2-3 times faster.
Note. Received results cover the project load only, excluding validation, diagramming, and further modeling tool feature usage.
Charts comparing project load memory and speed improvements between different modeling tool versions.
Three projects (sizes ranging from 1M to 2M) in 19.0 SP4 and the same projects in 2021x (sizes ranging from 750k to 1M) were used to run the tests.
Migration time is excluded because projects that had already been migrated were used for testing.
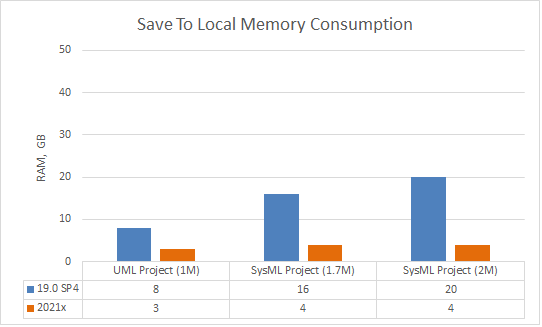
TWC Save to Local
In 2021x, great attention is paid to the memory consumption improvements. Saving a Teamwork Cloud project locally now requires less memory. For example, a 2M SysML project now consumes only 4GB of RAM, compared to 20GB in 19.0 SP4.
A chart comparing memory consumption when saving a TWC project as a local one between different modeling tool versions.
Project Merge has undergone considerable performance improvements. Modeling tool version 20.0 requires 3-4 times less memory to successfully merge two server project branches compared to 19.0 SP4.
Image Removed
A chart comparing merge memory consumption in different modeling tool versions.
Furthermore, the merge speed has increased by 20-70% in 20.0 compared to 19.0 SP4.
Image Removed
Charts comparing merge performance in speed and memory modes.
TWC Project Load Memory and Speed Improvements
Project load memory and speed improvements have been implemented for Teamwork Cloud. The modeling tool now requires only 2GB of heap to load a project (first and second time) when working with TWC projects compared to 8GB in 19.0 SP4. Additionally, as a result of the UML metamodel changes mostly, SysML projects are now opened 2-3 times faster.
N.B Received results cover the project load only, excluding validation, diagramming, and further modeling tool feature usage.
N.B A red border on a bar chart in the image below indicates a low memory occurrence during testing.
Image Removed
Image Removed
Charts comparing load memory and speed improvements between different modeling tool versions.
3 projects (sizes ranging from 1M to 2M) in 19.0 SP4 and 3 projects in 20.0 (sizes ranging from 750k to 1M) were used to run the tests.
Migration time is excluded because already migrated projects were used.
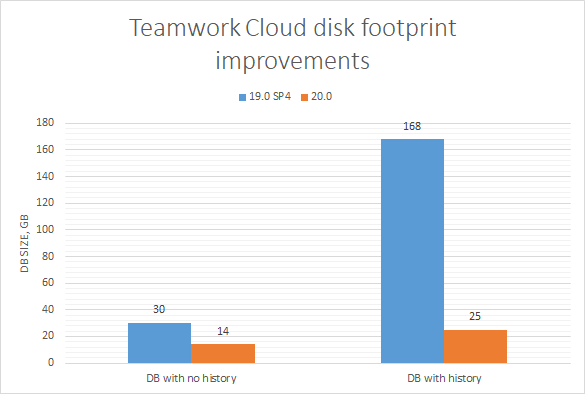
TWC Disk Footprint Improvements
Major TWC disk footprint-related changes are presented in this release. TWC 20.0 requires twice as less disk space for the same amount of projects with no history compared to TWC 19.0 SP4. In addition to this achievement, the disk size growth is cut nearly 5 times in TWC 20.0 compared to TWC 19.0 SP4 for those projects users work actively on.
Image Removed
A chart comparing TWC disk footprint between different modeling tool version
A database of 50 projects with 200 commits each was used to run the tests.
Project sizes ranged between 400k and 2.2M elements (average project size being 700k elements).
Partial Data Loading in Tables
Experience enhanced table loading and scrolling performance! Thanks to the newly-introduced Load Partial mode, data is now loaded in only visible rows, meaning that there is no need to wait until data is calculated in the entire table. What is more, fast scrolling has improved – it is now considerably smoother.
Image Removed
A chart comparing the opening time of Requirement Table having 7 standard columns with a different number of requirements.
Recent modeling tool performance improvements have led to an increase in the copying/pasting operation speed. Now you can copy and paste data noticeably faster for maximized productivity.
Image Removed
A chart comparing the copy&paste operation time in various scenarios.
Profiling Changes in the UML 2.5.1 Metamodel
Significant changes have been implemented to the UML metamodel for performance reasons. The InstanceSpecifications, Slots, and ValueSpecifications are no longer used to store profiling data. Instead, new model element types and properties are introduced while some have been removed (see the diagram below).
Image Removed
Profiling changes in the UML metamodel.
As shown in the figure above, Element references the TaggedValue that is used to specify the Boolean, Integer, Real, String, or Element values of the applied stereotype properties. This approach uses fewer model elements to store profiling data, which leads to a decrease in the total number of elements in SysML and UAF projects by 40-80%.
1 the project elements count is different due to the profiling data storing metamodel optimized in 2021x. 2 these memory requirements are indicative and may vary by project specifics.
N.B Expressions based on the previously implemented profiling data storing metamodel no longer work, meaning that they have to be updated manually.
Content block
id
419514524
Anchor
mi
mi
Modeling and Infrastructure
Layers Based on Legends
Diagrams can get extremely crowded as the model evolves. Therefore, highlighting a chosen piece of information, for example, only one specific aspect of the system becomes a great challenge. For your convenience, you can now filter diagrams by the selected Legend items to make only the necessary diagram layers stand out.
Filtering the diagram by the selected Legend item.
Direct the attention of your audience to the diagrams being presented! You can now present diagrams in full screen without showing such user interface components as model browser, diagram palette, status bar, and toolbars. That is not all! You can also define the sequence of diagrams to present one after another.
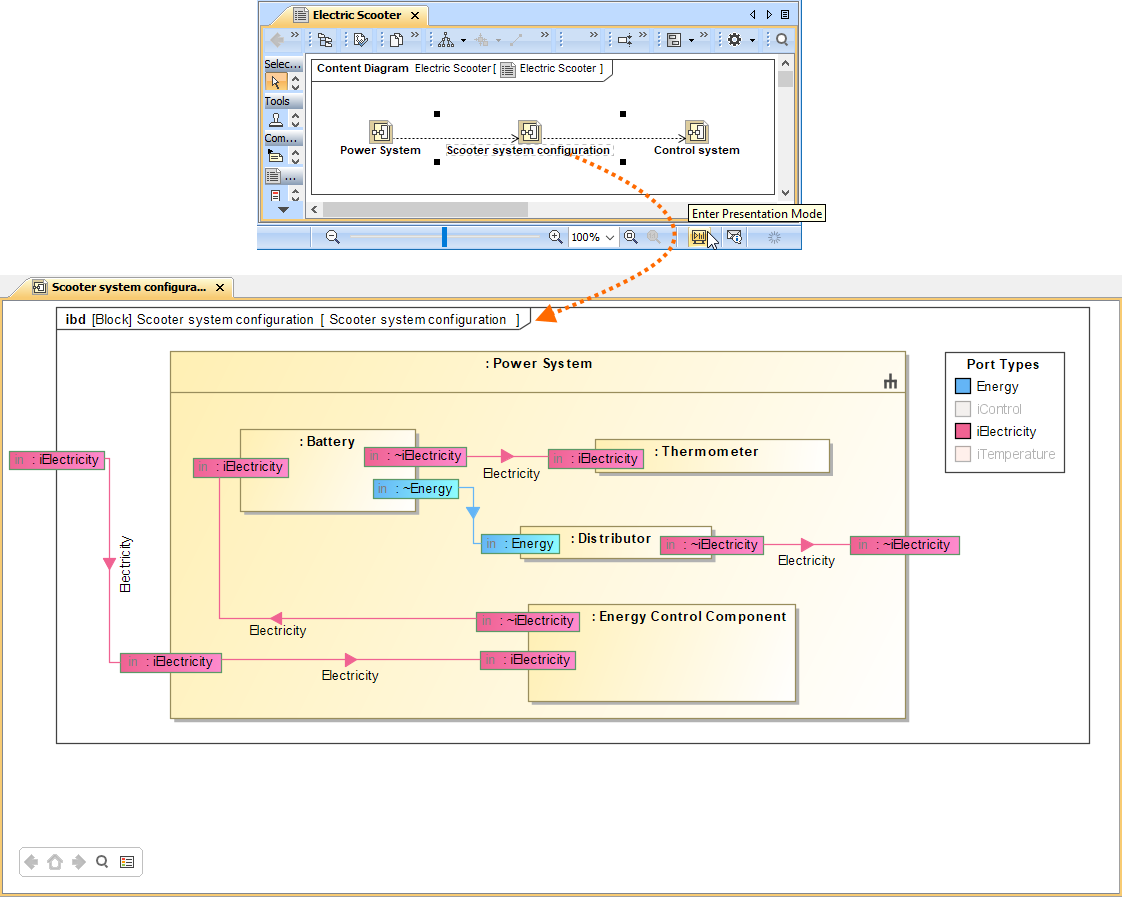
Seems like Legend creation is a tiresome activity? Not at all! From now on, you can create Legends easier than ever before – extract them automatically from the elements displayed on your diagram instead of relying on a manual creation. What is more, you can now automatically extract Legend items for the existing Legends. Once the Legend items are created, you can customize their adornments representation. They can now be displayed as rectangular shapes or extended lines to represent paths and shapes in greater detail.
Extracting the Port Types legend according to the elements displayed on the diagram as symbols.
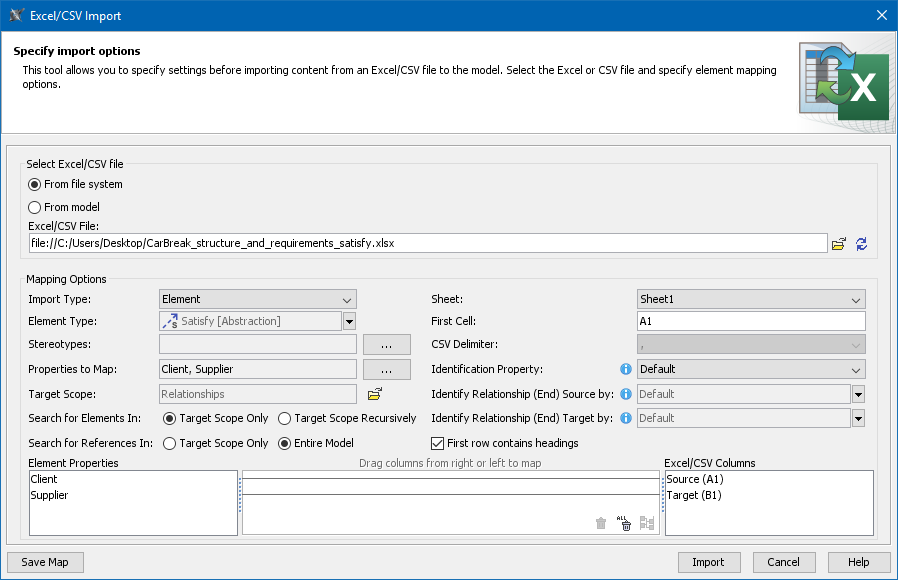
You can import data from an Excel/CSV file directly to the model without installing Excel and CSV Import Plugins (read more about discontinued products). From now on, the newly created Excel/CSV Import dialog brings an easy to use and clearly understandable graphical user interface. It allows you to import content with just a few clicks by selecting the Excel/CSV file and specifying element mapping options. Additionally, you can save your maps to reuse them, collect saved maps in groups, manage those groups, and use an entire group instead of a single map for data import.
The Excel/CSV Import dialog with specified options for satisfy relationship import.
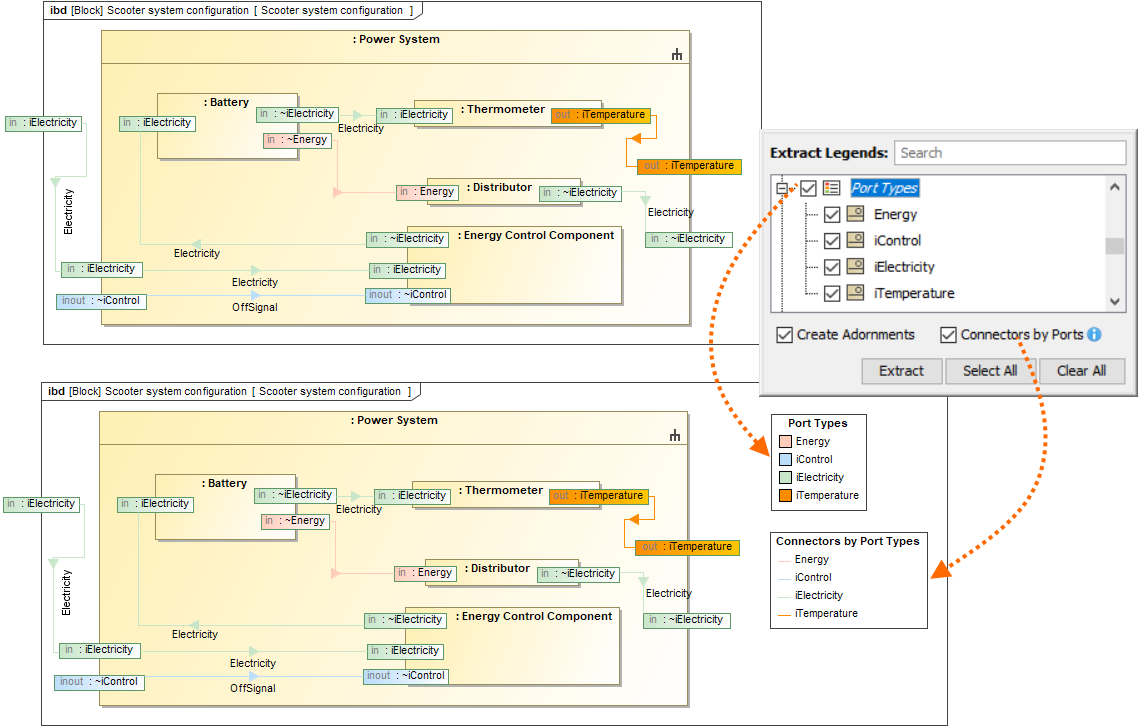
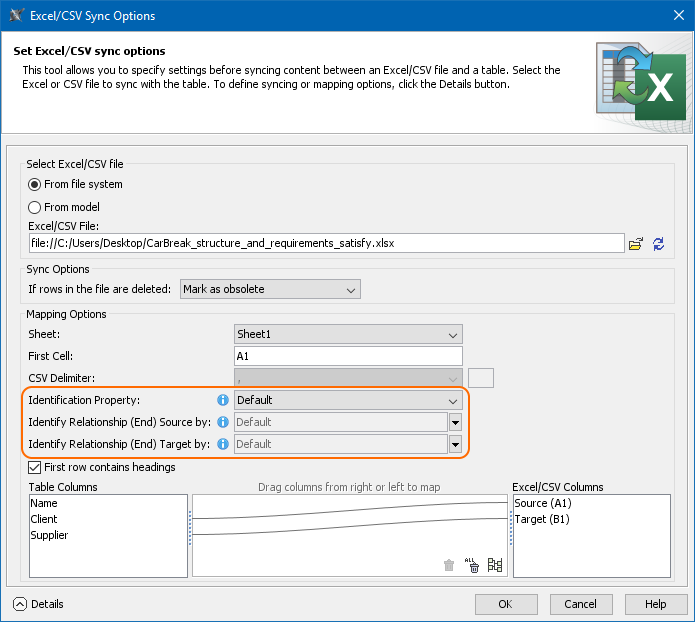
Three improvements to synchronize data between Excel or CSV files and a model:
Unique elements. Elements to be synchronized can now be identified not only by their name, but also by element property or tag value.
Direct relationships. From now on, you can import direct relationships between the source and target elements as easily as other elements.
Relationship ends. When importing relationships between different elements, you can select a specific property or tag to identify the source and target end of the relationship.
New mapping options in the Excel/CSV Sync Options dialog: Identification Property, Identify Relationship (end) Source by, Identify Relationship (end) Target by.
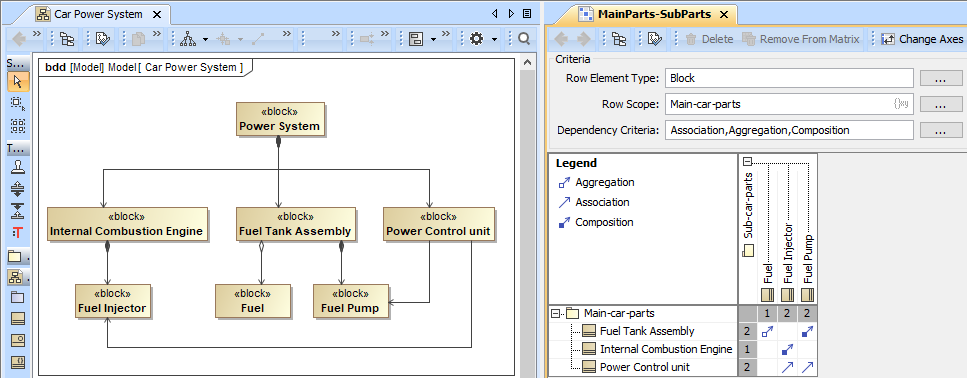
Composition and Aggregation Relationships in Dependency Matrix
You can now define relationships between the elements in your model more accurately! The latest release brings the ability to create and display Composition and Aggregation relationships in Dependency Matrix.
Creating and displaying Composition, Aggregation, and Association in Dependency Matrix.
Find the needed elements in the Select Element dialog faster! You can now filter elements by their types to narrow down the search results and thus perform your searches more effectively. That is not all! More performance-related improvements that help to find and select the needed elements faster are coming.
Performing an element search with the applied element type filter.
The smart autocompletion command Ctrl + Space now works for the Change Event expression in State Machine diagram.
The Jython 2.7.2 version is now supported.
Content block
id
419582860
Anchor
Colla
Colla
Collaboration
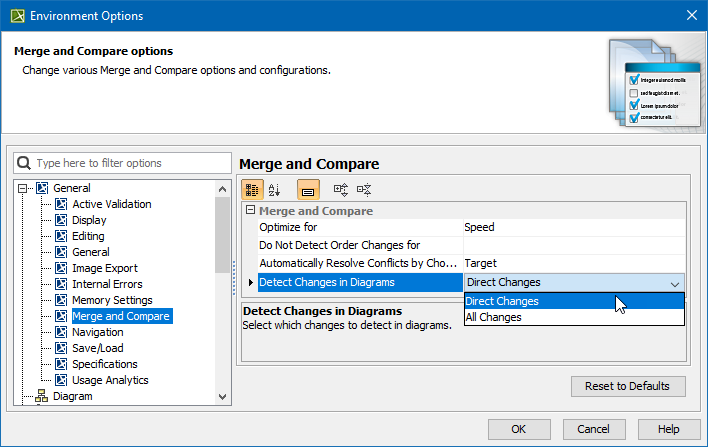
Detecting Changes in Diagrams During Merge
You can now specify in the Environment Options dialog whether to compare only the direct or all the changes in diagrams during the Project Merge and Project Comparison operations. By default, only the changes made by the user in loaded (open) diagrams are analyzed, leaving out unintentional diagram changes that occurred due to indirect changes in the model. This feature not only eases both merge and project comparison processes for the user since the number of diagrams with changes is considerably reduced but also optimizes modeling tool performance.
An Environment option to specify the changes to detect in diagrams.
The model merge has undergone further usability improvements. From now on, changes from the Target and Equivalent Changes are automatically hidden by default, meaning that only the Source changes are shown. As a result, fewer changes need to be reviewed by the user.
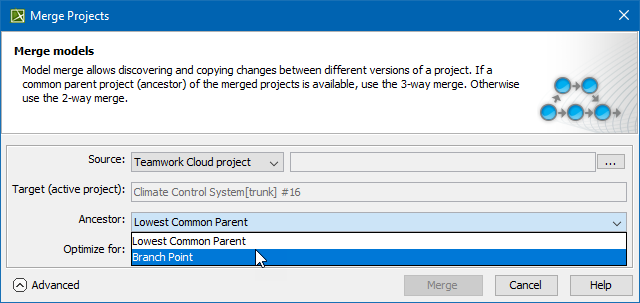
What is more, the model merge has been extended by adding a capability to select which ancestor calculation algorithm to use. You now have the freedom to choose a Branch Point as an ancestor for your merges. This is especially useful in those cases when merge results become too complex to understand and analyze due to previously rejected changes. By default, Lowest Common Parent ancestor calculation algorithm is used.
Selecting the ancestor for future merges in the Merge Project dialog.
An empowering tool of the Document Report Designer diagram is now available for conveniently drafting and designing new templates of Microsoft Word Document (DOCX) format. Discover more about Report Designer >>
Document Report Designer for drafting and designing new templates of Microsoft Word Document (DOCX) format.
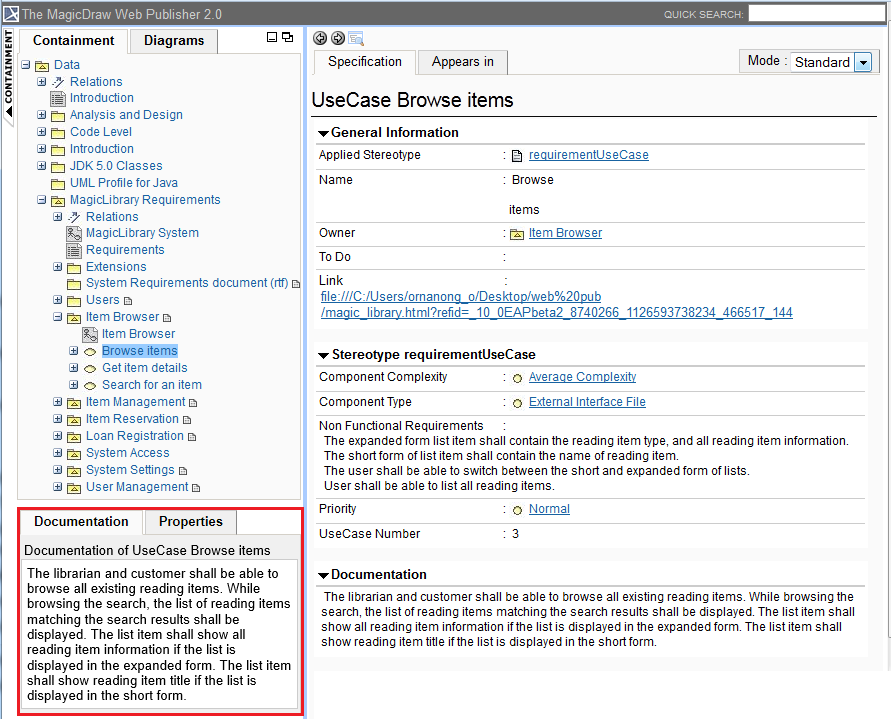
Web Publisher 2.0 now has the Quick properties panel, at the lower left similar to MagicDraw, show the documentation settings in the Documentation tab and properties in the Properties tab of elements selected in the diagram and from the Containment tree. Learn more about the new Quick properties panel >>
The Quick properties panel: Documentation and Properties tabs.